P4GPP
P4GPP: A GPU-Accelerated P4 Packet Processing
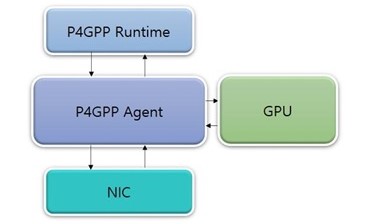
Recent works on P4 architectures such as programmable switches and SmartNICs face challenges in meeting the resource constraint of the devices, which interrupts the P4 program design innovation for numerous applications. In this paper, we explore GPU as the next P4 architecture target.
GPU contains a rich memory that can hold large register arrays and tables. Given P4’s parallelism on packet-level and program-level granularities, GPU’s massive concurrent computations units can accelerate P4 programs when compiled optimally. However, developers need GPU expertise to avoid kernel launches and branch blocking overheads.
We present P4GPP, a GPU packet processing framework with P4 abstraction. Developers can deploy P4 programs to P4GPP with ease without concerning the underlying GPU details. P4GPP compiler analyzes dependencies of P4 programs and generates a set of possible execution path graphs given the network policy. Then, it selects a graph with the least dynamic parallelism overhead and compiles the graph to optimized CUDA source codes that can execute both packets and programs concurrently with recent CUDA features. Our preliminary evaluations illustrate that P4GPP outperforms the CPU software router and both serialized and naively-implemented dynamic parallelism GPU programs.